
Dia 27 de maio, um documento com segredos do algoritmo da Pesquisa Google foi vazado e compartilhado em toda a Web, expondo detalhes sobre o funcionamento do buscador.
Uma notícia recente abalou a área de SEO no mundo inteiro: um vazamento de dados que supostamente revela segredos de algoritmo da Pesquisa Google. Os documentos, que estão disponíveis neste link, mostram como o Google armazena e manipula dados sobre conteúdo, links e interações do usuário.
Uma fonte anônima compartilhou com Rand Fishkin, veterano na área de SEO e fundador da SparkToro, o algoritmo vazado que expõe detalhes sobre a API do Content Warehouse. O vazamento inclui informações sobre fatores de ranqueamento, contradizendo várias afirmações públicas feitas pelo Google ao longo dos anos.
A seguir, conheça os detalhes da análise dos documentos realizada por Rand Fishkin e Mike Kling, CEO do iPullRank.
Como aconteceu o vazamento de dados da Pesquisa Google?
No início de maio, Rand Fishkin recebeu um e-mail interessante, no qual o remetente dizia ter acesso a milhares de documentos internos do Google que mostrariam a evolução do PageRank, como a empresa usa os dados de cliques, seu algoritmo de busca e muito mais.
A fonte, que se revelou no dia 28, chama-se Erfan Azimi. Ele conversou com Rand por chamada de vídeo e comprovou a veracidade dos documentos. Além disso, para se certificar que os dados eram legítimos, Rand também conversou com ex-Googlers e com Mike Kling, que o ajudou na análise dos documentos e preparou um artigo completo destrinchando as revelações do vazamento de algoritmo do Google.
São mais de 2.500 páginas de documentação da API, contendo 14.014 atributos que parecem vir do “Content API Warehouse” interno do Google. Com base no histórico do GitHub, o código foi carregado em 28 de março de 2024, sendo removido da plataforma somente em 7 de maio de 2024:

Sobre o vazamento de algoritmo do Google, Rand Fishkin fez uma observação importante: a documentação não mostra o peso dos elementos no algoritmo de busca, nem prova quais elementos são usados nos sistemas de ranqueamento. Por outro lado, o vazamento revela detalhes, que até então eram desconhecidos, sobre os dados que o Google coleta — e isso é ouro para SEOs.
Quem é Erfan Azimi?
Erfan é a fonte anônima de Rand, que se revelou em 28 de maio junto de suas motivações. No vídeo com seu pronunciamento público, Erfan conta que decidiu vazar os documentos que contém o algoritmo da Pesquisa Google para expor práticas internas que ele considera não transparentes e potencialmente prejudiciais para os usuários e a indústria de SEO.
Além disso, ele acredita que a divulgação dessas informações ajudará a promover uma maior transparência e responsabilidade nas operações do Google, além de fornecer insights valiosos sobre como o mecanismo de busca realmente funciona.
Quais as principais descobertas do vazamento de algoritmo do Google?
A seguir, confira quais são as principais descobertas do vazamento conforme a análise de Mike Kling:
1. Há uma métrica chamada “site authority”
Quem trabalha com SEO sabe muito bem: porta-vozes do Google frequentemente afirmam que não existe autoridade de domínio, também conhecido como domain authority (DA).
No entanto, Mike suspeita que essas afirmações sejam uma forma de omissão, já que ao dizer isso, os porta-vozes podem estar referindo-se especificamente à métrica “Domain Authority” da Moz.
Assim como também podem estar afirmando que não medem a autoridade de um site, criando uma confusão semântica que lhes permite evitar responder diretamente se calculam ou usam alguma métrica similar.
No documento, há menção de “site authority”, o que indica que existe sim tal métrica:
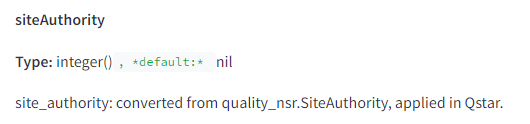
2. Os cliques importam muito para SEO
Apesar dos esforços de Gary Ilyes e John Mueller em minimizar o papel dos cliques, as evidências dos documentos e o próprio julgamento antitruste do Google indicam que métricas de cliques são essenciais para os algoritmos de ranqueamento.
No julgamento antitruste, o testemunho de Pandu Nayak, vice-presidente da Pesquisa Google, revelou os sistemas de classificação Glue e Navboost. O Navboost existe desde 2005 e utiliza dados de cliques para ajustar os rankings, além de que historicamente utilizava 18 meses de dados, agora reduzidos para 13 meses.
3. Existe uma sandbox para sites e autores de conteúdos novos
Porta-vozes do Google têm sido enfáticos ao afirmar que não existe uma “sandbox” onde sites são segregados com base na idade ou na falta de sinais de confiança. A documentação com o algoritmo vazado, no entanto, descreve o contrário:

Dessa forma, o hostAge ajuda o Google a saber há quanto tempo um site está ativo e se deve confiar nele, o que indica que sim, há uma sandbox.
4. Dados do Chrome são utilizados para busca orgânica
De acordo com pronunciamentos oficiais de porta-vozes do Google, os dados do Chrome não são usados na busca orgânica. Porém, entre os milhares de atributos encontrados na documentação, está o chromeInTotal, que mede as visualizações de sites no Chrome.
Também foi encontrado um módulo relacionado à pontuação de qualidade de página que usa dados do Chrome.
5. Os níveis de um site são tratados de forma diferente
Há evidências de que o NavBoost aplica suas pontuações em níveis de subdomínio, domínio raiz e URL, tratando diferentes níveis de um site de maneira distinta. Além disso, os dados do sistema NavBoost também influenciam o algoritmo Panda.
6. E-E-A-T continua sendo um fator de ranqueamento importante
O documento vazado comprova que sim, E-E-A-T é um fator importante para o ranqueamento. Portanto, como SEOs podemos seguir otimizando páginas de autores e priorizando a expertise e conhecimento ao produzir conteúdo.
Conforme analisado por Mike, o Google tenta determinar se a entidade da página é também o seu autor. Assim, o documento mostra atributos como “author” (lista de autores) e “isAuthor” (booleano indicando se a entidade é o autor do documento):

7. O posicionamento da página têm relação com links
O vazamento de algoritmo do Google também reforça a importância de links para alcançar bons resultados com tráfego orgânico.
Foi encontrado um atributo chamado sourceType, que indica a qualidade da página fonte do link, correlacionada o posicionamento da página nos resultados e seu valor:

Ou seja, isso significa que:
- TYPE_HIGH_QUALITY: são páginas de alta qualidade;
- TYPE_MEDIUM_QUALITY: são páginas de qualidade mediana;
- TYPE_LOW_QUALITY: são documentos de baixa qualidade;
- TYPE_FRESHDOCS: são documentos novos, sendo considerados de alta qualidade.
8. O Google considera as últimas 20 atualizações de uma URL
O Google armazena todas as versões de páginas indexadas ao longo do tempo, mas considera apenas as últimas 20 alterações ao analisar links. Isso reforça a ideia de que o Google mantém um histórico detalhado de mudanças, semelhante à Wayback Machine:

Assim, para obter uma “limpa” aos olhos do Google, é necessário fazer e indexar várias mudanças.
9. A autoridade da homepage é considerado para todas as páginas do site
De acordo com o vazamento de algoritmo do Google, é muito provável que o PageRank da homepage e o siteAuthority sejam usados como proxies para novas páginas até que seu próprio PageRank seja calculado:

10. O valor de um link é definido pela sua homepage
O Google decide o valor de um link com base na confiabilidade da homepage da página da fonte. O atributo homePageInfo indica se a página fonte é uma homepage e seu nível de confiança, com valores como NOT_HOMEPAGE, NOT_TRUSTED, PARTIALLY_TRUSTED e FULLY_TRUSTED.
Ou seja, ele verifica se é uma homepage, se é confiável, parcialmente confiável ou totalmente confiável.
11. O tamanho da fonte importa
O Google rastreia o tamanho da fonte das palavras nos documentos e do texto âncora dos links. Para isso, existe o atributo avgTermWeight, que mede o tamanho médio da fonte no corpo do documento. Para links, o atributo fontsize faz o mesmo, indicando que a formatação de texto pode influenciar a importância percebida das palavras e links.
12. Conteúdo curto nem sempre é um problema
De acordo com o vazamento de algoritmo do Google, o atributo OriginalContentScore sugere que conteúdos curtos são avaliados pela sua originalidade. Isso explica porque conteúdo “fino” (pouco extenso) nem sempre é um problema para a Pesquisa Google.
Apenas páginas consideradas com pouco conteúdo têm esse campo.
13. Os títulos da página devem ser otimizados
A documentação indica a existência de um titlematchScore, sugerindo que a correspondência entre o título da página e a consulta do usuário ainda é um fator importante para o Google. Ou seja, colocar suas palavras-chave-alvo no início do título continua sendo uma prática recomendada.
14. Não existe contagem de caracteres para títulos de página ou snippets
Conforme as informações de algoritmo vazadas, não existem métricas para contar o comprimento de títulos de página ou snippets.
A única medida de contagem de caracteres encontrada na documentação é o snippetPrefixCharCount, usado para determinar o que pode ser incluído como parte do snippet. Isso confirma que títulos longos não são ideais para cliques, mas são aceitáveis para rankings.
15. O Google verifica as datas de publicação
O Google dá muita importância a resultados recentes, associando várias datas às páginas publicadas:
- bylineDate: Data explícita na página, mostrada nos snippets dos resultados de busca.
- syntacticDate: Data extraída da URL ou do título do documento.
- semanticDate: Data derivada do conteúdo da página, âncoras e documentos relacionados.
Por isso, é essencial especificar uma data e ser consistente com ela em dados estruturados, títulos de página e sitemaps XML. Datas conflitantes podem prejudicar o desempenho do conteúdo.
16. Sites focados em vídeos têm tratamento diferente
Se mais de 50% das páginas de um site tiverem vídeos, o site é considerado focado em vídeos e será tratado de maneira diferente pelo Google:

17. YMYL têm suas próprias classificações
O Google possui classificadores que geram pontuações para YMYL Health e YMYL News. Eles também fazem previsões para “fringe queries” (consultas raras) para determinar se são YMYL. Dessa forma, a avaliação de YMYL é feita no nível de chunks (partes do documento), sugerindo que todo o sistema é baseado em embeddings.
18. Embeddings são usados para medir a relevância de páginas
De acordo com o Google, os embeddings de texto são uma técnica de PLN (processamento de linguagem natural) que podem ser utilizados para pesquisa semântica e classificação de texto. Ou seja, são construídos para que uma máquina consiga entender a busca feita pelo usuário.
Dessa forma, o Google está utilizando os embeddings para vetorizar páginas e sites, comparando os embeddings das páginas com os dos sites para avaliar o quão fora do tópico a página está. O atributo siteFocusScore captura o quanto o site é focado em um único tópico, enquanto o siteRadius mede o desvio das páginas em relação ao tópico central do site.
19. O Google pode estar prejudicando sites pequenos de propósito
O Google possui um atributo específico que indica se um site é um “pessoal e pequeno” (smallPersonalSite). Embora não haja uma definição clara, é possível que o Google utilize isso para promover ou rebaixar tais sites. Considerando o impacto negativo em pequenos negócios após a Atualização de Conteúdo Útil, é surpreendente que essa funcionalidade não seja usada para apoiá-los.

20. As informações de registro de domínio são armazenadas
O Google armazena informações de registro de domínio em nível de documento composto. Isso inclui:
- createdDate: Número de dias desde 1 de janeiro de 1995 em que o domínio foi criado.
- expiredDate: Número de dias desde 1 de janeiro de 1995 em que o domínio expirou.
Essas informações são provavelmente usadas para determinar o “sandboxing” de novos conteúdos e domínios que mudaram de proprietário. Isso pode ter um peso maior com a introdução da política de spam de abuso de domínios expirados.
Lembrando que, no contexto do Google, “sandbox” refere-se a um mecanismo que pode restringir temporariamente a visibilidade de um site ou conteúdo na busca.
Conclusão
O vazamento de algoritmo do Google, compartilhado por Rand Fishkin, revelou práticas detalhadas sobre como a empresa manipula e classifica informações na Web.
Esses documentos reforçam a importância de fatores que já eram discutidos na comunidade de SEO, como dados de cliques, autoridade de domínio, e dados de registro de domínio.
No entanto, a documentação também introduziu conceitos como o “sandbox” para novos sites e a influência dos embeddings de tópicos. Essas revelações destacam a complexidade dos algoritmos de busca do Google, assim como a necessidade de estratégias SEO que priorizem qualidade, relevância e consistência.
Por fim, vale reforçar que o vazamento de algoritmo não foi confirmado pelo Google, que até então não se pronunciou sobre os detalhes existentes no documento.

